KMP(Knuth-Morris-Pratt)算法:
字符串查找算法(简称为KMP算法)可在一个字符串S内查找一个词W的出现位置。一个词在不匹配时本身就包含足够的信息来确定下一个匹配可能的开始位置,此算法利用这一特性以避免重重复查找之前出现的字符。
我对MKP的认识:其归属于DP问题,核心的思想在于对要查找的字符串进行处理——寻找最长的前缀。然后通过记忆化数组的方式,跳过不可能成功匹配的字符串位置,从下一个可能的位置进行搜索。利用要查找字符串的特性,利用其前缀和后缀的共同部分来简化搜索过程。
算法原理:
简单的暴力搜索无非就是从每个可能的index开始,与要查找的字符串进行比较。 而KMP则会跳过已经匹配的部分,以维基百科的说明为例,简单概括过程:
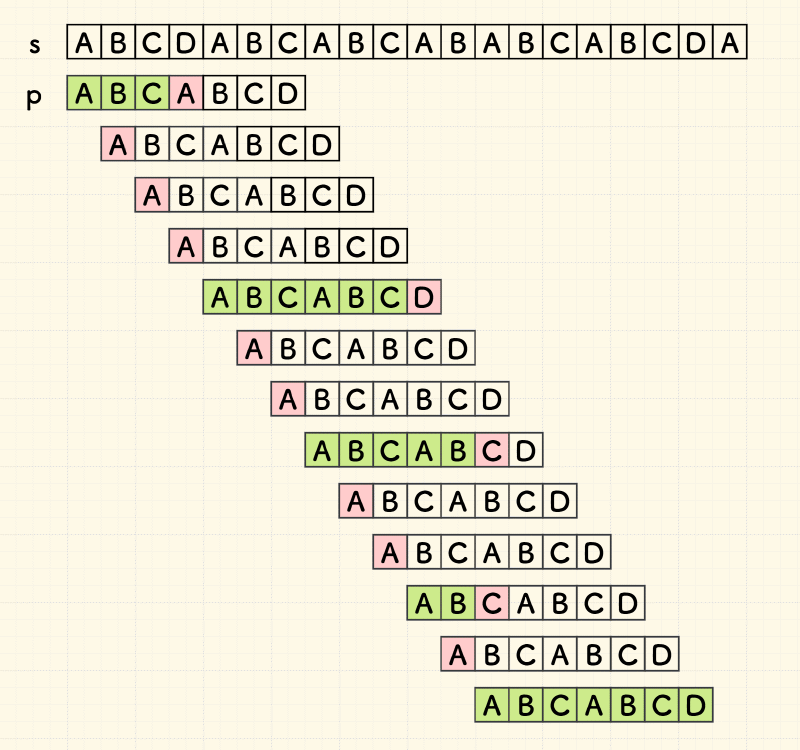
要查找的字符串W=“ABCDABD”,
给定字符串S=“ABC ABCDAB ABCDABCDABDE”
为例说明查找过程:
S: ABC ABCDAB ABCDABCDABDE
W: ABCDABD
- S[3](=’ ’)与W[3](=‘D’)不匹配,所以跳过;从S[4]开始,与W[0]进行比较。
S:ABC ABCDAB ABCDABCDABDE
W:ABCDABD
- 从S[4]开始比较,当位于S[10](=’ ’)时,与W对应的字符不匹配;但是此时可以注意到,"AB“在“ABCDAB“的头尾处均有出现——这意味着,尾部的“AB”可以作为下一次比较的起点。
- 所以下次从index = 8的位置:
S:ABC ABCDAB ABCDABCDABDE
W:ABCDABD
- 即A开始进行匹配。
应用题目实战:
LeetCode 28. Find the Index of the First Occurrence in a String
题目实战日后补充说明
同时推荐一个算法可视化工具:
algorithm-visualizer_KMP
如有遗漏或错误,欢迎补充纠正